Hello everyone,
Very happy with my S2 device and data coming from it in Oxford UK.
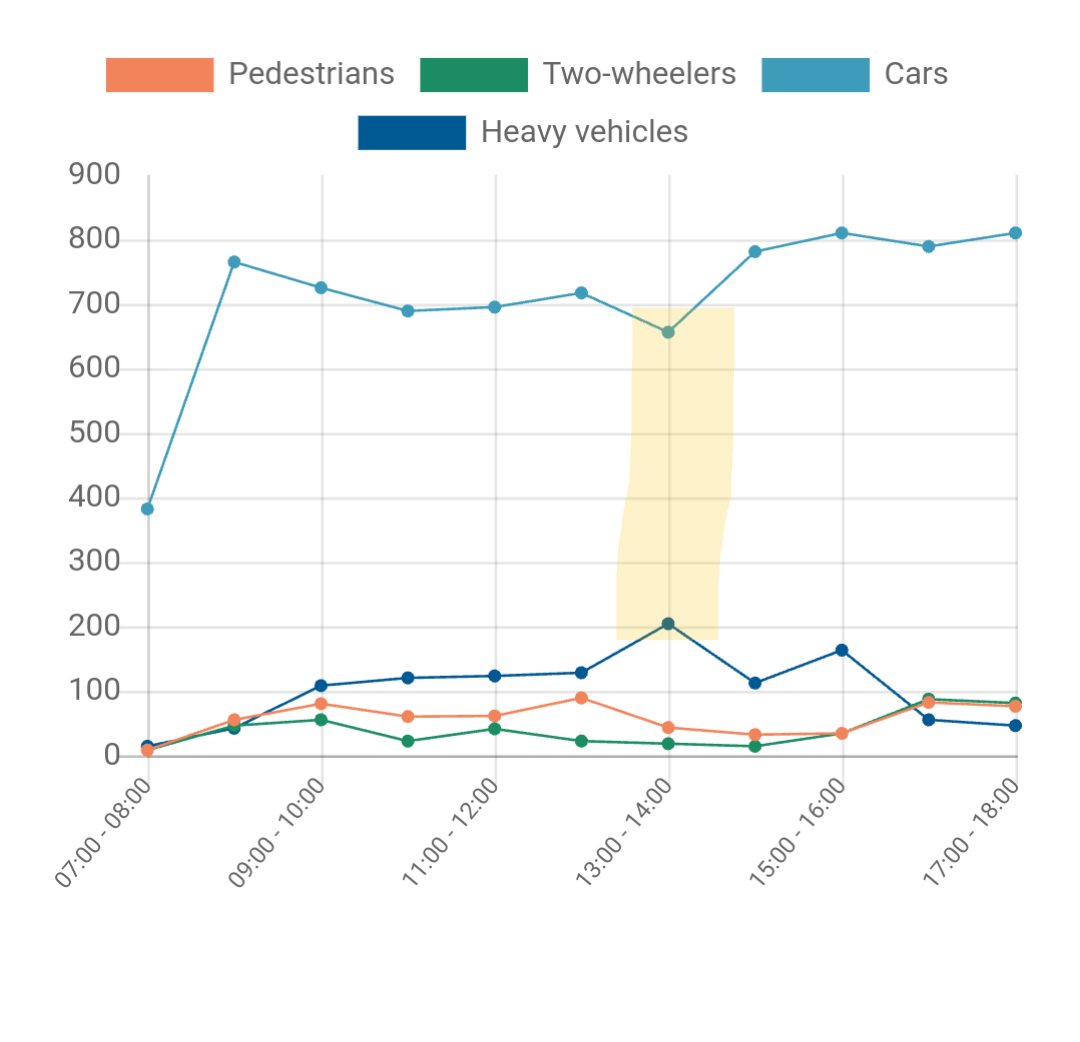
I do note occasionally though some slight concerns in accuracy, for example here on just today’s data there looks like the suggestion of an artifact in car/HV binning.
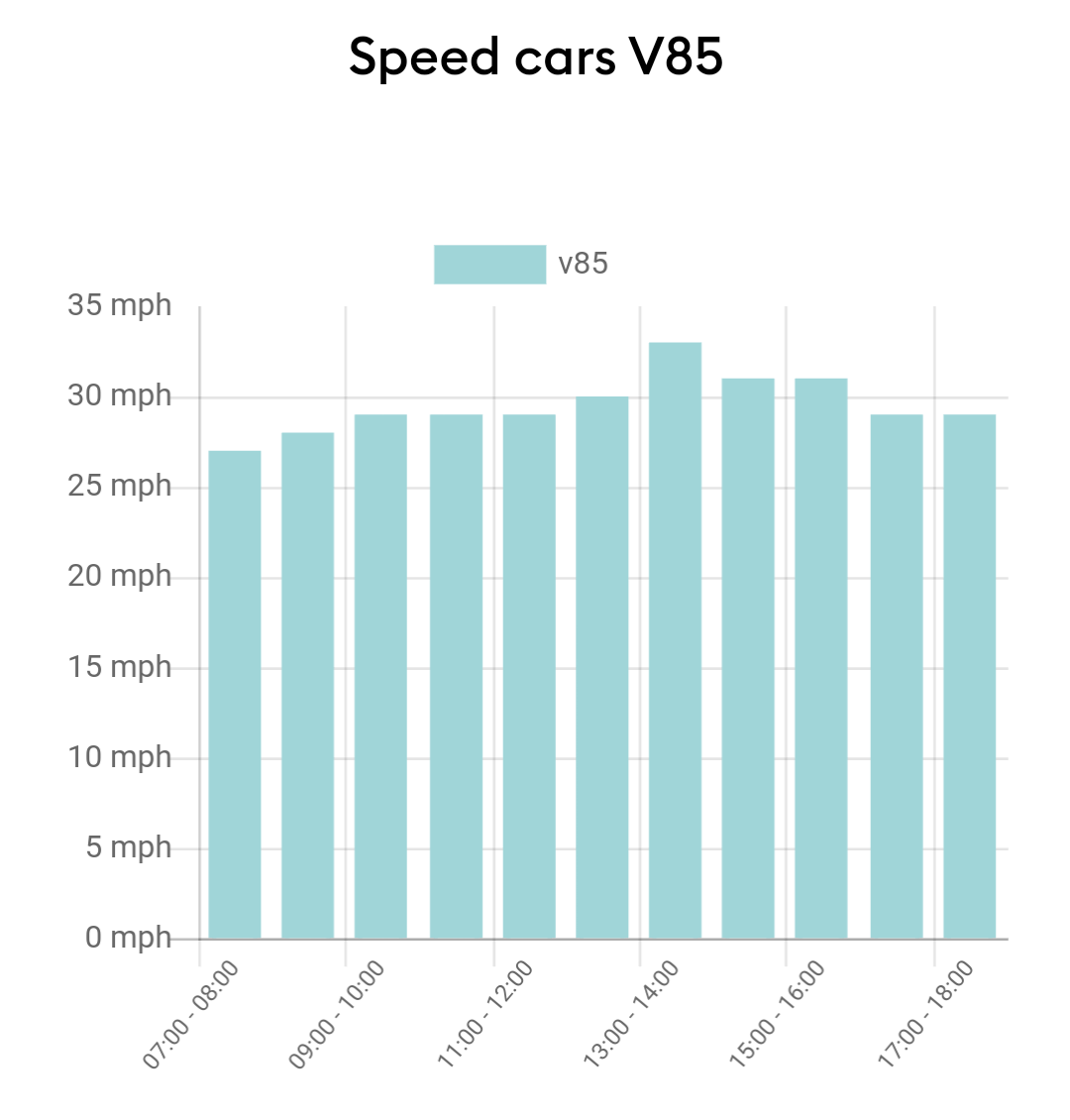
And then looking at V85 speeds there is matching suggestion of artifactual high value at the same time:
<Can’t embed more than one bit of media, see reply below>
This has me a little worried that errors in speed, vehicle length and hence vehicle binning are correlated because of the method used (time to move one self-length). You’ll note that counts are pretty high at this site so we are not short of measurements.
In parallel I have been thinking that it would be straightforward of me to provide the device with reasonably accurate distances across the ROI at different vertical pixel coordinates.
I appreciate that the emphasis is on building as simple a device/method as possible but it strikes me that a little optional device-host-supplied info could improve accuracy.
Best regards,
Danny
Thanks so much @dannyaxford
We definitely plan to make the data something that can be annotated by users in due course. As you can image, this is not totally straightforward, but the richness that this can bring will be very useful indeed.
The artifact you noticed is odd, I agree. I suspect that this will be something caused by shadows at a particular angle which may make some cars look a larger and different shape to normal and therefore be recognised as small trucks. If it affects slower cars more (i.e. they sit in the light longer), then it will have a knock-on effect on the V85 calculation.
It does only appear to happen at a very particular time, so hopefully this will not severely impact the data quality.
This is a very different approach to the way we would track and measure objects, so I don’t think this is something we can do.
What might be possible is to take part in our upcoming data validation exercise where you can supply manual counts to check against the device data. If we spot major issues what we can do is record suitable video from the location and use this to better train our AI model. This will have the same benefit, but also not require other users to have to calibrate their own devices (as we would update the improved algorithm for all).
Look out for some upcoming emails on this subject
Thanks for your reply and thoughts Rob. I’d certainly be up for contributing manual count data and video as appropriate. I’m sure others would be too.
Cheers, Danny
1 Like